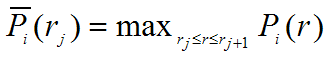 (for each query)
(for each query)IR Homework Page
Homework #1 :Evaluation Measures
Homework #2 :Classic Retrieval Models
Homework #3 :Query Expansion and Term Reweighting
Homework #4 :HMM/N-gram-based and PLSI Retrieval Models
Homework #1 :Evaluation Measures
The the query-document relevance information (AssessmentTrainSet.txt) for a set of queries (16 queries) on a collection of 2,265 documents is provided. An IR model is then tested on this query set and save the corresponding ranking results in a file (ResultsTrainSet.txt) . Please evaluate the overall model performance using the following two measures.
1.
Interpolated Recall-Precision Curve:
(for each query)
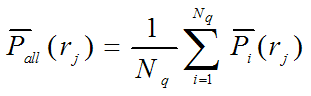 (overall performance)
(overall performance)
2. (Non-interpolated) Mean Average Precision:
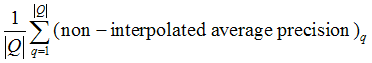
, where "non-interpolated average precision" is "average precision at seen relevant documents" introduced in the textbook.
Homework #2 :Classic Retrieval Models
A set of text queries (16 queries) and a collection of text documents ( 2,265 documents) is provided, in which each word is represented as a number except that the number "-1" is a delimiter. Implement an information retrieval system based on the Vector (Space) Model as well as different term weighting schemes. The query-document relevance information is in "AssessmentTrainSet.txt". You should evaluated you system with the two measures described in HW#1.
Homework #3 :Query Expansion and Term Reweighting
You should augment the function of query expansion and term reweighting into your retrieval system that has been built in HW#2. Either (automatic) reference feedback or local analysis can be adopted as the strategy for it, but local analysis is preferred.
Homework #4: HMM/N-gram-based and PLSI Retrieval Models
You have to implement either the HMM/N-gram-based retrieval model or the PLSI retrieval model. A set of query exemplars associated with topic information (a list of 819 queries and query files) is provided. In addition, the topic information of the document collection and a word-based unigram language model estimated from a general corpus are provided as well .
Homework #5: A Web-based IR System
A zip file Word_Information.rar is provided.
Each file in it stands for a spoken document,
and each line of a document
contains the following information of a word:
POS_IN_DOC WD_NAME WD_ID Begin_Time-1 End_Time Acoustic_Score Confidence_Score1 Confidence_Score2
You can skip the word "SIL" (which means a silence segment).
1. Use overlapping character bigrams as index
terms to build your own retrieval
system.
2. Implement the inverted file structure for doc indexing.