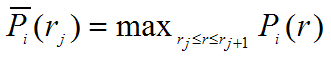 (for each query)
(for each query)
Information Retrieval and
Extraction
Spring 2016
Homework Webpage
Homework #1 :Evaluation Metrics for IR
The the query-document relevance information (AssessmentTrainSet.txt) for a set of queries (16 queries) and a collection of 2,265 documents is provided. An IR model is then tested on this query set and save the corresponding ranking results in a file (ResultsTrainSet.txt) . Please evaluate the overall model performance using the following two measures.
1.
Interpolated Recall-Precision Curve:
(for each query)
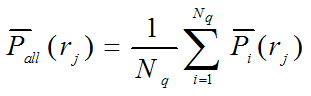 (overall performance)
(overall performance)
2. (Non-interpolated) Mean Average Precision:
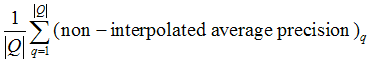
, where "non-interpolated average precision" is "average precision at seen relevant documents" introduced in the textbook.
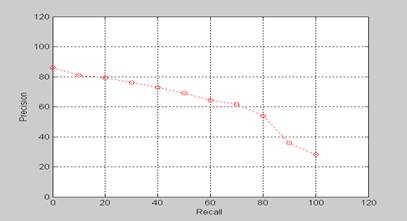
Example 1: Interpolated Recall-Precision Curve
Example 2: (Non-interpolated) Mean Average Precision
mAP=0.63787418
3. Normalized Discounted Cumulated Gain (NDCG) :
Homework #2 : Retrieval Models
A set of text queries (16 queries) and a collection of text documents ( 2,265 documents) is provided, in which each word is represented as a number except that the number "-1" is a delimiter.
Implement an information retrieval system based on the Vector (Space) Model (or Probabilistic Model, Generalized Vector Space Model, Latent Semantic Analysis, Language Model, etc.). The query-document relevance information is in "AssessmentTrainSet.txt". You should evaluated you system with the two measures described in HW#1.
Homework #3 : Relevance Feedback and Query Expansion
Integrate the function of query expansion and term re-weighting into your retrieval system that has been built in Homework #2. Either (automatic) reference feedback or local analysis can be adopted as the strategy for it, but local analysis is preferred.